

Introdução
Estruturas de dados modernas, tendem cada vez mais adotar serviços e ferramentas que possibilitem as chamadas "ad hoc" queries. Este conceito é muito utilizado em Data Science, sendo uma forma simplificada de acesso a um determinado conjunto de dados e experimentações de modelos.
Consultas ad hoc, também podem ser utilizadas em conjunto com ferramentas de BI como Tableau, Power Bi, QuickSight etc.
Pensando em AWS, o serviço que melhor se encaixa dentro desta característica é o Athena. O preço desta peça tecnológica pode parecer atrativo, 5USD a cada 1 TB de dados escaneados, porém, caso sua arquitetura não esteja aderente a boas praticas de armazenamento, modelagem e segurança, o Athena pode virar o seu maior pesadelo.
Este artigo tem como objetivo demonstrar como a escolha do melhor formato de arquivo e compressão de dados, pode ter um impacto significativo em seus custos.
Ainda é relevante salientar que muitos dos pontos aqui abordados possuem uma abrangência muito maior do que a delimitação deste artigo. Tanto os tipos de arquivos e suas respectivas compactações vão distribuir uma cadeia de custos por todo o seu data lake. Portanto, as orientações e conclusões que veremos aqui são aplicáveis a muitos outros serviços da AWS.
Sobre os tipos de arquivo
Ao pensar em estruturas de dados na AWS, um dos pontos de partida é entender os possíveis formatos de arquivos disponíveis para utilização. Vamos abordar os prós e contras ao utilizar os seguintes tipos de arquivos: AVRO, Apache ORC, Apache Parquet, CSV e JSON.
Avaliando cada um dos tipos de arquivo, sempre encontraremos vantagens e desvantagens, porém, AVRO, ORC e Parquet apresentam vantagens significativas em relação ao CSV e JSON, fazendo com que faça muito sentido que os times de arquitetura e engenharia de dados deem preferência a estes tipos de arquivo.
Um ponto relevante dentro da escolha de um determinado formato de arquivo é entender a diferença entre um formato baseado em colunas e um formato baseado em linhas. Há uma diferença significativa em como os dados são armazenados para arquivos com formato baseado em colunas ou linhas. Isso implica em afirmar que escrever e ler dados armazenados em um determinado arquivo, tem um custo diretamente associado ao formato de arquivo escolhido, seja ele baseado em linhas ou colunas.
Como nossos dados são organizados?
Temos o seguinte exemplo de dado para aprofundar essa discussão sobre formatos de arquivos:

Este conjunto de dados é bem simples, visando apenas servir como base para a explicação sobre os tipos de formato de arquivos.
Vamos pensar o como esses dados são estruturados em um arquivo em formato de linhas.

Podemos ver que a primeira linha ocupa todo o espaço do arquivo, até o final dele.

A segunda linha, tem a estrutura semelhante, onde todos os dados são dispostos por toda a extensão do arquivo.
E essa estrutura segue no mesmo formato do inicio até o fim do preenchimento do arquivo. Sempre preenchendo todas as colunas para todas as linhas em uma única operação.
Agora vamos visualizar como se comporta uma arquivo com colunas. Vejam a primeira coluna.

Um arquivo em formato de colunas exige que cada coluna seja preenchida de uma única vez. Isso pode trazer benefícios, como lidar com registros que possuem os mesmos tipos de dados, mas pode trazer desvantagens, como a necessidade se realizar múltiplas interações para armazenar um único registro.
Vejam a segunda coluna:

Fica claro que a cada nova coluna, um novo conjunto de dados do mesmo tipo vai complementar uma mesma informação já existente. Mas quando olhamos para o formato de linhas, é bem claro que cada linha possui todo o conjunto de dados necessários para representar a informação desejada.
Vamos utilizar alguns conjuntos de cores para detalhar melhor algumas diferenças entre os formatos de arquivos:

Neste exemplo as cores representam o tipo de dados. Sendo o amarelo a representação de um dado do tipo Date, Verde representa nossas Strings e Roxo nossos números inteiros. Vejamos uma comparação entre as linhas e as colunas dos nossos tipos de formatos de arquivos. A imagem abaixo, busca representar os tipos de dados utilizados em cada uma das linhas de maneira sequencial, como se estivéssemos criando o arquivo linha a linha. Veja:

Pensando no preenchimento do arquivo de forma sequencial, o nosso programa deve trabalhar de forma continua, com tipos de dados distintos. Esta informação é de extrema importância quando estivermos falando sobre compressão.
Observe agora, a mesma analogia de cores quando estivermos falando de um formato de arquivo baseado em colunas. Veja:

Já conseguimos observar uma clara e objetiva diferença entre os dois tipos de formato de arquivo. É evidente que o arquivo baseado em colunas pode exigir uma menor necessidade de troca de tipo de dado para o software que esta escrevendo e lendo este determinado arquivo. Ainda assim, neste ponto, é importante ressaltar que para a escrita de arquivos o formato baseado em linhas ainda será mais fácil e muitas vezes mais performático de gravar dados. Mas dependendo da sua necessidade, aqui já temos uma clara percepção que existirão cenários onde o formato de arquivos baseado em colunas será mais vantajoso.
Agora vamos adicionar mais colunas, apenas para enriquecer nosso exemplo:

Para realizar a leitura deste arquivo temos que levar em consideração o formato de arquivo utilizado para salvar estes dados. Pensando em um formato de arquivo baseado em linhas, sempre teremos que resgatar todos os registros de uma determinada linha para depois selecionar as colunas que desejamos. Em nosso exemplo, um usuário quer consultar os dados do jogo entre os times E e F primeiramente nosso programa irá recuperar a linha que contem esses registros:

Após recuperar a linha, nosso programa seleciona os dados das colunas desejadas. Supondo que queremos apenas o número de gols do mandante e do visitante, assim como os nomes dos times, então nosso dados ficaria desta forma:

Ao observar o processo de selecionar dados em um arquivo com formato baseado em linhas, concluímos uma importante questão, toda vez que fazemos uma consulta, independentemente da quantidade de colunas que queremos visualizar, o "scan" em nosso arquivo será sempre o mesmo, pois o primeiro passo para acessar nossos dados é capturar todas as colunas de uma determinada linha. Mais a frente neste artigo, iremos para o exemplo prático, usando esses mesmos dados no Athena e iremos comprovar estas conclusões.
Agora vamos observar o mesmo processo considerando um arquivo com formato baseado em colunas:

Ao realizar uma consulta neste arquivo, as etapas para a consulta são semelhantes. Primeiramente, o nosso programa deve determinar qual ou quais linhas devem ser lidas e posteriormente ele selecionará as colunas desejadas. A grande diferença esta na forma como esses dados são organizados. Em um arquivo com formato baseado em colunas, nosso programa vai ignorar as colunas que não foram solicitadas pelo usuário, diminuindo drasticamente o "scan" executado em nosso arquivo. Como podemos ver na representação abaixo, nossa consulta, parece exigir menos esforço computacional para apresentar o mesmo resultado. Ao executar nossos exemplos no Athena, estes pontos poderão ser comprovados. Veja:

Esta representação, busca exemplificar que a consulta em um arquivo com o formato baseado em colunas deve primeiramente selecionar a linha ou conjunto de linhas necessárias para a consulta, já considerando o número de colunas desejadas pelo usuário. Isso significa que ao usuário diminuir a quantidade de colunas desejadas, ele diretamente esta diminuindo o "scan" do programa para retornar esses dados. É importante ressaltar que esta análise é comparativa em relação a tipos de formato de arquivos baseados em colunas e linhas, essas mesmas referências não devem ser aplicadas em bases relacionais.
Tipos de arquivo e seus formatos
Neste ponto, temos uma visão geral de como se comparta esses dois formatos de arquivos. Mas quais extensões de arquivos suportam formatos baseados em colunas ou linhas?

De forma objetiva temos a seguinte composição: CSV, JSON e AVRO para arquivos com formato baseado em linhas e Apache ORC e Apache Parquet para arquivos com formato baseado em colunas.
A partir desde ponto precisamos avaliar qual o objetivo do nosso dado e principalmente se esse dados possui um estilo de carga de trabalho voltado para leituras mais intensas ou gravações mais intensas. A pergunta correta que temos que fazer para a nossa modelagem de dados é: "Ao longo do tempo, passaremos mais tempo gravando registro ou lendo registros?". Esta pergunta é vital para definir qual o melhor formato de arquivo devemos utilizar.
Pensando em arquivos com formato baseado em colunas, temos o seguinte cenário considerando performance para gravação e leitura de arquivos:

Podemos notar que arquivos com formatos baseado em colunas tem alta performance para leitura de dados mas o desempenho deixa a desejar quando o assunto é gravar dados.
Aprofundando esta discussão, podemos dividir os formatos de arquivos entre os tipos mais comuns conforme ilustrado abaixo:

Compactação de arquivos
Outro ponto importante para se considerar quando estamos pensando em armazenamento de nossos dados é em relação a compactação dos nossos arquivos. Cada formato de arquivo tem um comportamento distinto quando o assunto é compactação. Além disso, ainda temos diferenças significativas nos algoritmos de compactação disponíveis para cada tipo e formato de arquivo.
Para arquivos com formatos colunares, os algoritmos de compressão são aplicados coluna a coluna. Isso nos dá uma vantagem quanto a compressão uma vez que o algoritmo aplica a compressão em dados que possuem o mesmo tipo. No nosso exemplo de dados podemos visualizar isso melhor:
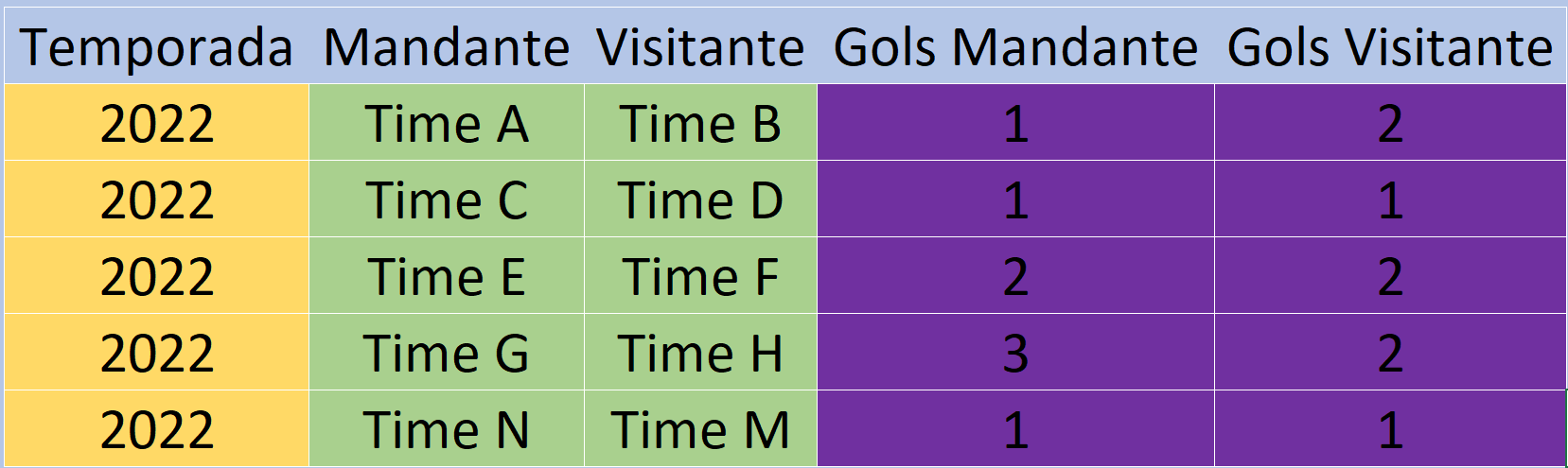
Temos de forma muito clara que cada coluna possui um tipo especifico de dado. A coluna temporada possui dados do tipo Date, a coluna Mandante possui dados do tipo String, a coluna visitante possui dados do tipo String, a coluna Gols Mandante possui dados do tipo Inteiro e a coluna Gols Visitante possui dados do tipo Inteiro. Uma vez que nosso algoritmo de compressão trabalha de forma individual, coluna a coluna, ele sempre obterá a melhor performance e eficácia possível para comprimir aquele tipo de dado.
Este nosso mesmo exemplo deixa claro que um algoritmo de compressão terá mais dificuldade para comprimir o exato mesmo dado que esta disponível em um arquivo de formato baseado em linhas. Isso acontece pois cada linha possui um conjunto distinto de tipos de dados, fazendo com que o algoritmo de compressão tenha dificuldades em selecionar a melhor opção para compressão e com isso o resultado final será um arquivo com menor percentual de compressão em relação aos arquivos com formatos baseado em coluna.
Aprofundando um pouco mais nos algoritmos de compressão, temos os seguintes disponíveis:

Ao analisar a tabela com os algoritmos que estão disponíveis, temos uma visão clara que temos uma escolha que vai definir qual o nosso compression rate e em contra paridade faremos uma escolha que impactará diretamente na velocidade de compressão, por consequência no custo da compressão também.

Human-readable?
Chegamos num ponto interessante. Saber se um tipo de arquivo pode ser ou não lido por um humano, pode vir a ser um ponto determinante para escolha do seu tipo e formato de arquivo.
CSV e JSON são formatos que podem ser lidos por humanos. Nesta perspectiva, esses formatos trazem uma clara vantagem para leitura e edição manual.
ORC, Parquet e AVRO são formatos que não podem ser lidos por humanos. Quando fazemos essas afirmações estão levando em conta o acesso direto de um humano aos arquivos. Quando fazemos o uso de ferramentas como o Athena, essa não é uma informação relevante, uma vez que todos os formatos aqui abordados (menos ORC) serão lidos dentro do serviço da AWS e humanos terão fácil acesso as informações contidas nos arquivos.
Objetivo de cada tipo de arquivo
Parquet: é uma ótima opção para casos onde temos dados aninhados, complexos e que precisam ser acessados com alta frequência. Ele armazena seus elementos em uma árvore e usa o algoritmo de fragmentação e montagem de registros para ajudar a acelerar a pesquisa - você pode encontrar mais informações sobre isso aqui no Dremel Paper: https://research.google/pubs/pub36632/
ORC e AVRO também podem lidar com dados aninhados, mas não foram construídos explicitamente com esse tipo de funcionalidade em mente. Eles têm outros objetivos de alta prioridade, como compactação ou capacidade de divisão, como seu recurso mais importante. Obviamente não podemos nos esquecer que AVRO possui uma grande capacidade de alteração do seu schema o que é uma grande vantagem quando trabalhamos com dados que estão em constante evolução, porém um grande desperdício de recursos, uma vez que a flexibilidade do schema já é algo muito bem consolidado em ferramentas como o Glue e seus Crawler e Catalog.
Por Fim temos o CSV e JSON, pensando em data lake deveríamos nos afastar o máximo possível destes formatos.
Paralelismo
O quão divisível é o seu arquivo? Ao falarmos em armazenamento de dados em arquivos, temos um problema referente ao tamanho deste arquivo, quanto mais dados, maior o tamanho de um determinado arquivo. Quanto maior o arquivo, maior o esforço de processamento de um programa para ler, gravar, compactar e manter este arquivo. Para resolver o problema relacionado com o tamanho excessivo de nossos arquivos temos o conceito de "Data Chunk" (pedaços de dados). Precisamos entender se podemos dividir o nosso dado entre múltiplos arquivos e o quão fácil é baseado no formato e tipo de arquivo que temos disponível para escolher.
Qual a vantagem em dividir nosso dado em múltiplas partes? A paralelização de seu processamento de dados pode melhorar muito o desempenho, e isso requer um tipo de arquivo que permita a divisão dos dados em múltiplos arquivos, logo uma primeira resposta para nossa pergunta é ganho de performance.
Quando nossa carga de trabalho este concentrada em sistemas de arquivos distribuídos, como o Hadoop (incluindo EMR), é vital que um arquivo possa ser divido em várias partes. Uma vez que seu dado pode ser dividido em múltiplas partes, o Hadoop poderá distribuir e operar seus arquivos utilizando técnicas de paralelismo. Se nosso tipo de arquivo não permite uma divisão dos arquivos, então teremos que construir um algoritmo que seja responsável por esta divisão, este tipo de pratica gera um maior esforço dos engenheiros de dados e muitas vezes tem grandes problemas de performance por gastar mais tempo buscando a divisão dos arquivos do que processando o dado em si. Por esse motivo estaremos sempre em busca dos "Splittable Files", tipos de arquivos possuem a capacidade nativa de serem divisíveis em múltiplos arquivos.
AVRO, Apache ORC e Apache Parquet respeitam as características de "Splittable Files" que buscamos. A imagem abaixo ilustra bem o como devemos considerar nossos tipos de arquivo neste quesito:

Por fim, trazemos uma tabela que tenta responder a maior parte das perguntas sobre o tipo e formato de um determinado arquivo. A tabela da uma resposta binária para um determinado atributo, como por exemplo sim ou não para se o arquivo é Splittable. Além disso a tabela traz uma escala de cores, onde o roxo representa uma capacidade que não é boa ou o arquivo não possui aquela capacidade. O amarelo indica uma capacidade do arquivo que não tem uma performance adequada. O verde indica que o tipo de arquivo atende aos melhores requisitos deste atributo. Por fim, o azul indica que é o melhor cenário possível. Esta tabela ainda trás uma informação que muitas vezes é relevante, a capacidade de manutenção do Schema dos arquivos. Não abordamos esse tema de forma profunda por considerar que o Glue (Crawler e Catalog) fornecem os mecanismos necessários para lidar com mudança de Schema independentemente do tipo de arquivo. Neste ponto, vale uma reflexão, se as ferramentas propostas não suportam sua necessidade de alteração de Schema, isso significa que a ferramenta esta defasada ou você possui problemas de modelagem? Essa simples pergunta tem um grande significado, de nada adianta utilizar as melhores técnicas de processamento, tipo de arquivo, formatos baseados em linhas ou colunas, softwares e serviços em nuvem se o seu dado não passou por um bom processo de modelagem. Vamos para a tabela comparativa:

Serviços AWS
Nós vamos dar uma atenção especial a alguns serviços da AWS. Basicamente nosso artigo gira ao entorno do IAM, S3, Glue e Athena. Sendo que o Glue se divide entre alguns serviços, Glue Catalog, Glue Crawler, Glue Jobs, Glue Trigger e Glue Workflows.
IAM
Iremos utilizar o IAM role para autorizar o Glue Crawler capturar os schemas dos arquivos contidos em nossos buckets. Além disso o IAM também será utilizado para autorizar o Glue Jobs a ler os arquivos CSV e gravar os arquivos JSON, Parquet e ORC. Para isso iremos criar uma Role que autorize essas operações.
S3
Utilizaremos o S3 como nosso data lake. Nossos arquivos ficaram armazenados no S3.
Glue Crawler
Utilizaremos o Glue Crawler para fazer a captura dos schemas dos arquivos CSV. A partir dos schemas capturados fazemos os registros no Glue Catalog.
Glue Catalog
Utilizaremos o Glue Catalog para armazenar o metadado dos arquivos. O Glue Jobs utilizará o Glue Catalog para ter acesso aos dados de origem e utilizará o Glue Catalog para armazenar o metadado dos dados de destino (para cada tipo de arquivo que vamos criar).
Glue Jobs
Responsável pela execução dos nossos ETL.
Glue Trigger
Responsável por fornecer os gatilhos para nosso Crawler e ao nosso Jobs.
Glue Workflows
Responsável por utilizar o os triggers para orquestrar a execução dos nossos crawlers e jobs.
Athena
Ferramenta de BI que utilizaremos para execução de nossas query ad hoc.
Terraform
Utilizamos o terraform para criar nossa infraestrutura. Código do terraform. Não esqueça de modificar os nomes dos buckets!
Lab
Vamos utilizar os serviços acima para demonstrar as características que foram abordadas na referência bibliográfica deste artigo. Não se preocupe os passos a seguir visam demonstrar o resultado final do artigo. No final do artigo teremos um link para o vídeo completo do lab para que você possa reproduzir facilmente. O Custo total deste lab, incluindo 2 execuções do Glue Jobs é de $0,20. Importante ressaltar que existem os impostos que serão cobrados apenas ao final do mês.
Iremos utilizar a base de dados de todos os jogos do Brasileirão Série A dos anos de 2003 até 2020. Você pode encontrar esta base no Kaggle ou fazer o download aqui em nosso artigo.
Criamos 5 buckets. 1 para cada tipo de arquivo. Para facilitar iremos importar nosso arquivo com a base em CSV no bucket brasileirao-pizzocsv. Um ponto de atenção aqui, cada bucket tem um nome único em toda a AWS, desta forma, modifique o terraform para criar os buckets com os seus nomes, isso diminuirá as chances de problemas ao executar o terraform em seus computadores. ArquivoCSV Faça o download do arquivo ao lado e faça upload no S3 Bucket. Está disponível também todo o conjunto de dados já particionado ArquivoCSVParticionado
Está disponível para download código fonte python do Glue Jobs tanto para o arquivo não particionado quando para as partições: glue_job_source.py e glue_job_source_partitiion.py
Após realizar o download de todos os arquivos, é importante que o main.tf, os 2 arquivos .py, a base não particionada e as partições fiquem no mesmo diretório. Caso contrário o terraform não conseguirá encontrar os arquivos e não conseguirá criar os recursos em sua conta aws.
Ao executar nosso terraform, temos a seguinte estrutura abaixo que foi criada: nosso arquivo dentro do respectivo bucket. Mais uma vez lembramos, modifique o nome dos buckets!

Nosso crawler é automaticamente executado pelo Workflow do Glue.

O Glue Crawler irá salvar os metadados do seu arquivo no GlueCatalog

Ainda no Glue Catalog será possível observar todos os campos do metadado do nosso arquivo.

Nosso terraform cria o nosso Glue Jobs em modo script, mas no modo visual você poderia visualizar algo muito parecido com a figura abaixo:

Configuramos o nosso source para ler nosso bucket com o arquivo CSV original.

No ApplyMapping não fizemos nenhuma modificação. Mas aqui você pode e deve alterar e limitar o número de colunas a serem processadas. Em um artigo futuro pretendo abordar de forma pratica as melhores praticas do Glue. (Para o dado Particionado, modificamos a nomenclatura da coluna ano_campeonato para ano_campeonato_no)

Na imagem abaixo temos a configuração para geração do nosso arquivo JSON. O Glue jobs irá criar e atualizar a tabela json no Glue Catalog.
Abaixo podemos visualizar o Jod Details onde temos que informar o nome do nosso job assim como a Role que será utilizada. Informa a IAM Role que criamos no terraform (AWSGlueToRun). Informe 0 no campo number of retries, caso nosso Glue Jobs falhe não queremos que ele tente novamente, lembre-se o Glue Jobs é pago e será cobrada cada execução. Fique atento para não cometer falhas e ter execuções causando cobranças desnecessárias. Lembrando que a execução do Glue Crawler e Glue Jobs é feita automaticamente pelo nosso Workflows.

Abaixo podemos visualizar a estrutura gráfica do nosso workflows:

Aba Monitoring, podemos monitorar o andamento da execução de nossos jobs.

Após finalizar o processamento dos arquivos vamos para o Athena realizar algumas queries e comparar o scan do Athena para cada tipo de arquivo.
Logo ao entrar no Athena, do lado esquerdo iremos visualizar nosso Database e nossas tabelas.

Na posição superior direita é possível encontrar o Workload o qual você faz parte e executará as queries. Atenção você necessita de um Workload. Caso queira controlar os custos do Athena você pode limitar o Scan query a query o criar uma limitação de Scan por Workgroup. Ao trabalhar com grandes volumes de dados em múltiplos times recomenda-se aplicar as configurações de controle para evitar gastar exorbitantes.
Ao clicar em settings você pode e deve configurar um local para armazenar os resultados das queries. Não esqueça de realizar esta configuração.

Agora vamos para os resultados de nossas queries. Vou executar uma query em cada tabela do respectivo arquivo que armazena os dados. Seguiremos a ordem JSON, CSV, AVRO e Parquet.
As seguintes Queries foram Executadas:
SELECT * FROM "brasileirao"."brasileirao_pizzocsv SELECT * FROM "brasileirao"."json" SELECT * FROM "brasileirao"."jsoncompactado" SELECT * FROM "brasileirao"."avro" SELECT * FROM "brasileirao"."parquetgzip" SELECT * FROM "brasileirao"."parquetsnappy" SELECT * FROM "brasileirao"."brasileirao_pizzocsv" where ano_campeonato = 2003 SELECT * FROM "brasileirao"."json" where ano_campeonato = 2003 SELECT * FROM "brasileirao"."jsoncompactado" where ano_campeonato = 2003 SELECT * FROM "brasileirao"."avro" where ano_campeonato = 2003 SELECT * FROM "brasileirao"."parquetgzip" where ano_campeonato = 2003 SELECT * FROM "brasileirao"."parquetsnappy" where ano_campeonato = 2003 SELECT ano_campeonato, time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."brasileirao_pizzocsv" where ano_campeonato = 2003 SELECT ano_campeonato, time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."json" where ano_campeonato = 2003 SELECT ano_campeonato, time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."jsoncompactado" where ano_campeonato = 2003 SELECT ano_campeonato, time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."avro" where ano_campeonato = 2003 SELECT ano_campeonato, time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."parquetgzip" where ano_campeonato = 2003 SELECT ano_campeonato, time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."parquetsnappy" where ano_campeonato = 2003"
É importante ressaltar que arquivos AVRO e CSV compactados não são suportados pelo HIVE. Dessa forma o Athena não conseguirá fazer a leitura deste dado. O mesmo problema ocorre em serviços como o QuickSight. Por este motivo não temos queries para as tabelas com AVRO e CSV compactados.
Outro ponto importante é sobre a compactação do Parquet. Em nossos resultados conseguimos o mesmo percentual de compactação com Snappy e Gzip. Desta forma os resultados das queries são idênticos, por este motivo estamos exibindo na tabela de resultados apenas os dados do Parquet SNAPPY. No vídeo do Lab podemos observar como tudo ocorreu. O link para o vídeo do Lab está disponível no final deste artigo.
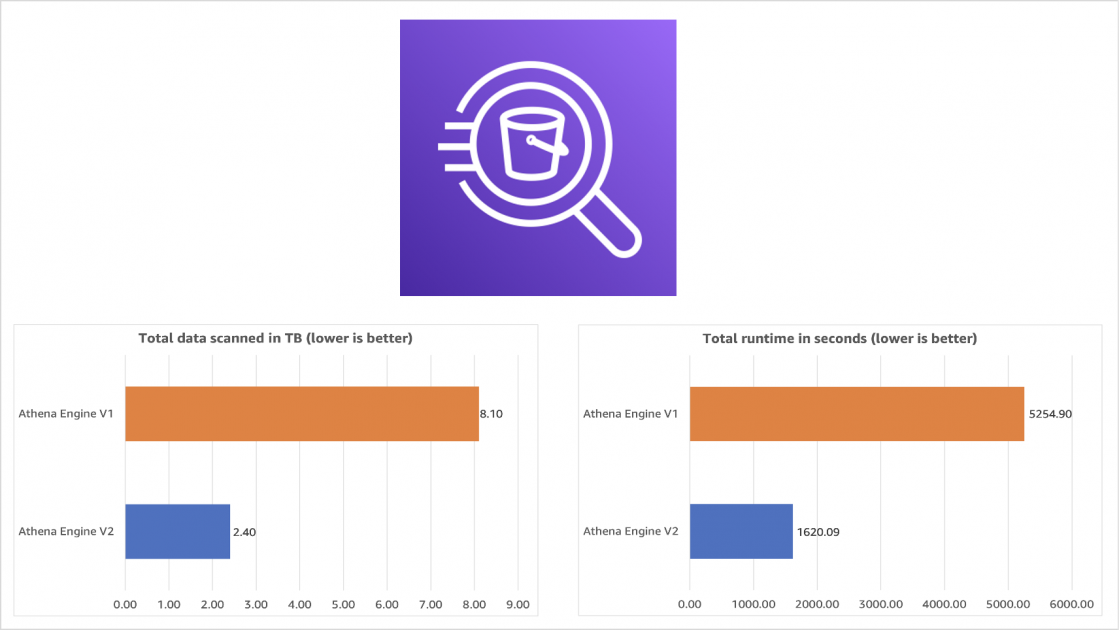
Após as 3 séries de queries chegamos ao seguinte resultado:

É possível observar que o tipo de arquivo Parquet teve uma vantagem obtendo um menor scan possível em comparação com a mesma query que foi executada em outros tipos de arquivo. Mas para realmente chegarmos a conclusão final, precisamos abortar outro aspecto importante do armazenamento de dados. O Split de arquivos.
Para aprofunda a avaliação, usamos a capacidade de split dos nossos arquivos. O CSV não tem a capacidade de gerar os dados divididos entre arquivos de forma eficiente, mas partimos de um arquivo CSV que foi feito split a partir de um código python. Desta forma nascemos com o dado já particionado. A partição escolhida foi o ano do campeonato, o que representa a temporada do futebol brasileiro.
Temos as seguintes partições:

Em nosso vídeo vamos demonstrar todo o passo a passo para execução dos crawlers. Vale conferir. Aqui partiremos diretamente ao ponto, com as tabelas já disponíveis para consulta no Athena. Podemos visualizar que a tabela possui uma indicação que o dado está particionado.

Vamos iniciar a nossa bateria de execução de queries. Agora vamos também incluir a clausura where e elevar o nível de comparação. Para deixar a comparação mais interessante, nós duplicamos a coluna ano_campeonato. A coluna original agora se chama ano_campeonato_no e a nova coluna que representa nossa partição baseada na temporada do campeonato brasileiro se chama ano_campeonato. Essa será uma importante informação para entender o como o armazenamento de dados se comporta não apenas no Athena nem na AWS mas em qualquer Cloud Provider e em qualquer Serviço Cloud Native.
As seguintes queries foram executadas em nosso dado particionado:
SELECT * FROM "brasileirao"."brasileirao_pizzocsv SELECT * FROM "brasileirao"."json" SELECT * FROM "brasileirao"."jsoncompactado" SELECT * FROM "brasileirao"."avro" SELECT * FROM "brasileirao"."parquetgzip" SELECT * FROM "brasileirao"."parquetsnappy" SELECT * FROM "brasileirao"."brasileirao_pizzocsv" where ano_campeonato = 2003 SELECT * FROM "brasileirao"."json" where ano_campeonato = 2003 SELECT * FROM "brasileirao"."jsoncompactado" where ano_campeonato = 2003 SELECT * FROM "brasileirao"."avro" where ano_campeonato = 2003 SELECT * FROM "brasileirao"."parquetgzip" where ano_campeonato = 2003 SELECT * FROM "brasileirao"."parquetsnappy" where ano_campeonato = 2003 SELECT * FROM "brasileirao"."brasileirao_pizzocsv" where ano_campeonato = 2003 and ano_campeonato = '2003' SELECT * FROM "brasileirao"."json" where ano_campeonato = 2003 and ano_campeonato = '2003' SELECT * FROM "brasileirao"."jsoncompactado" where ano_campeonato = 2003 and ano_campeonato = '2003' SELECT * FROM "brasileirao"."avro" where ano_campeonato = 2003 and ano_campeonato = '2003' SELECT * FROM "brasileirao"."parquetgzip" where ano_campeonato = 2003 and ano_campeonato = '2003' SELECT * FROM "brasileirao"."parquetsnappy" where ano_campeonato = 2003 and ano_campeonato = '2003' SELECT time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."brasileirao_pizzocsv" where ano_campeonato = 2003 and ano_campeonato = '2003' SELECT time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."json" where ano_campeonato = 2003 and ano_campeonato = '2003' SELECT time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."jsoncompactado" where ano_campeonato = 2003 and ano_campeonato = '2003' SELECT time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."avro" where ano_campeonato = 2003 and ano_campeonato = '2003' SELECT time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."parquetgzip" where ano_campeonato = 2003 and ano_campeonato = '2003' SELECT time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."parquetsnappy" where ano_campeonato = 2003 and ano_campeonato = '2003' SELECT time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."brasileirao_pizzocsv" ano_campeonato = '2003' SELECT time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."json" where ano_campeonato = '2003' SELECT time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."jsoncompactado" where ano_campeonato = '2003' SELECT time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."avro" where ano_campeonato = '2003' SELECT time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."parquetgzip" where ano_campeonato = '2003' SELECT time_man, time_vis, gols_man, gols_vis FROM "brasileirao"."parquetsnappy" where ano_campeonato = '2003'"
Após a execução das 5 séries de queries temos o seguinte resultado:

Com o uso das partições é evidente o ganho real de custo e performance que temos em nosso conjunto de dados. É importante também reparar que o Json pode em alguns momentos demonstrar uma boa performance e parecer ser uma boa escolha, porém é importante ressaltar, o Json só obteve melhores resultados quando utilizamos o Select *. Utilizar esse tipo de query não é uma praticamente recomendada e vai degradar a performance e aumentar os custos de qualquer solução. Dito isso, os resultados demonstram um ganho de performance e potencial redução de custos ao empregar o uso de Parquet em nossa estrutura de dados na AWS. Resultados semelhantes são esperados em qualquer Cloud Provider.
Conclusão
Fizemos uma análise direcionada para determinados serviços e condições fortemente relacionadas ao nosso Cloud Provider. Ainda assim, é necessário ponderar que outros serviços e outros Cloud Providers podem vir a ter os mesmos ganhos aqui apresentados.
A partir da base de arquivos que foram disponibilizados, podemos aferir a qualidade do dado utilizado. De fato, podemos observar que o dado não é dos melhores, possui falhas como campos em branco, não utilizados. Essa característica de baixa qualidade na modelagem pode de fato afetar o desempenho de certos tipos de arquivos como AVRO o que pode demonstrar uma desvantagem que em outros cenários não seria tão grande. Mas de fato, todo o cenário foi proposto para demonstrar vantagens do Parquet, mas temos a absoluta certeza que existirão cenários onde esta vantagem será menor, apesar de sempre existir.
Nós fizemos o uso do Glue Crawler e Catalog não apenas para nos ajudar com a conversão dos arquivos, mas também para líder com os Schemas dos arquivos da forma mais simplificada possível. Não é raro encontrar certos defensores de determinados tipos de arquivo que usam as capacidades de evolução de Schema como justificativa infundada para adoção de certos tipos de arquivos. O Auxilio dos serviços de Data Analytics de seu Cloud Provider podem ajudar na gestão do seu Schema, não precisamos ficar presos a padrões ineficientes devido a uma característica que mal fazemos uso.
Outro ponto importante são as partições. De forma inequívoca aferimos que as partições são um dos principais padrões a serem implementados em nossas estruturas de armazenamento de dados. Apesar disso, é necessário sempre pensar e utilizar as partições da melhor forma possível, pois um dado mal particionado poderá causar problemas e excessivas cargas de trabalho para manter este dado com um bom selo de qualidade. Definitivamente não podemos abandonar os processos de modelagem de dados, pois eles vão garantir que possamos atender a todas as melhores praticas e características para o nosso processo de armazenamento, processamento e disponibilização de dados.
Abaixo temos uma tabela que ilustra o ganho de cada tipo de arquivo em comparação com os outros tipos:

A tabela de ganhos esta organizada com a coluna a esquerda indicando o tipo de dado que esta sendo comparado com a primeira linha da tabela. Isso significa que cada célula a esquerda teve os resultados comparados com cada uma das colunas indicando se o tipo de dado teve ganho ou perdeu desempenho comparado ao tipo de dado na coluna.
Vamos exemplificar com o JSON GZIP. O JSON GZIP teve 97% de ganho em relação ao JSON, 93% em relação ao CSV e 94% em relação ao AVRO mas perdeu 43% em relação ao Parquet Snappy.
Analisando a linha do Parquet Snappy, ele apresenta ganho em relação a todos os outros tipos ilustrados na tabela. Ganhos de 98% em relação ao JSON, 96% em relação ao CSV, 96% em relação ao AVRO e 43% em relação ao JSON GZIP.
Desta forma, a tabela de ganhos demonstra como o parquet vai impactar diretamente na performance e no custo de todos os seus processos de dados em nossas data lakes na nuvem.
Por fim, ao utilizar os serviços de Data Analytics da AWS sempre devemos estar atentos nos tipos corretos de arquivos a serem utilizados. As mesmas verificações que fizemos neste artigo, se aplicam em outros serviços como RedShift, QuickSight, EMR, Glue, Kinesis Data Analytics, QuickSight entre outros serviços menos impactados mas ainda relevantes dentro do contexto de Data Analytics.
Para finalizar, convido a todos a assistir o vídeo com o passo a passo dos resultados aferidos neste artigo:
Referências:

Publicado por
Solutions Architect | AWS Certified
#aws #datalake #dataanalytics #athena #glue #terraform #data #cloud #s3 Um estudo direcionado para alguns dos problemas que podemos enfrentar no dia a dia com um data lake em qualquer cloud provider.